
In this article, I’ll be taking you through the practical steps of creating a SQL Server routine, based on the stages I described in my last article ‘How to write SQL code’. I don’t make a claim that this is a standard method of doing it, since I’ve never come across one. All I can say is that it works for me. It will describe a simple routine purely to emphasize the advantages of a structured approach whatever the size of the project, and to make the size of this article manageable.
For this exercise, we want to design and build a new routine that searches any text-based column that you specify in any table for instances of a string. It returns all the ‘hits’ or matches in their context in order to make it easy to scan content. We want to do this in order to quickly find all occurrences of a string in the chunk of text in which it occurs, in any column of any table. I’m going to try to make it generally useful, but I’ve been asked to provide it as a tool for an actual production use as part of an admin process for monitoring website content.
1/ Up-front time estimation and planning
I’ve only got six hours I can spend, so I’ll have to cut corners. At this stage, I’ve only a vague idea of what is wanted and a slight feeling of apprehension, since the result isn’t a subset of the data set. A single tuple could furnish us with several ‘hits’ or matches, and there is no way of telling at this stage whether we need to use a wildcard search. I’ll do a quick Gantt chart to give me a rough idea of progress.
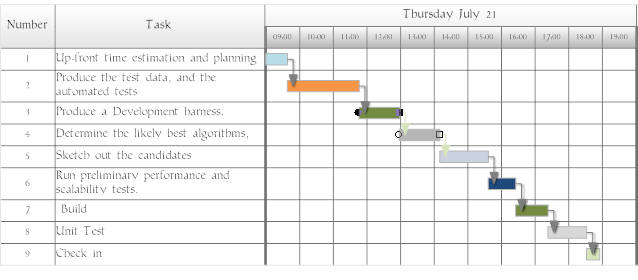
Obviously, this didn’t take very long at all since I have a template ready-made. (I use SmartDraw)
So what do we really want in the results? The amount of data in the system suggests to me that a simple wildcard search will be sufficient. I like creating ‘inversions’ for doing fancy searches such as proximity searches and ‘google-style’ searches, but this, I reckon, isn’t going to be one of those times. I’ll need to test that assumption too!
Another worry is how to go about making this generic, so I’ll aim for a barebones design and put in extra niceties if I have some time spare after getting the basic system working. In other words, I’m ‘time-boxing’.
2/ Produce the test data, and the automated tests
Before we do anything else, we need some simple data for component-testing. In this case, we can grab some sentences from my first article on ‘How to write T-SQL Code’ and make them into a quick table for testing the various parts of the routine, and we’ll add a few ‘edge’ cases just to catch the obvious errors. This will do for initial component testing and we can keep it handy if we need to alter anything. We can even store it for ‘Assertion-testing’ . We’ll tuck it into a View since that is easier to maintain, but normally we’d probably just use the statement directly to produce the ‘table’
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE VIEW testSentences /* this view is specifically designed for component, and assertion testing of string routines and inline code. Alter any of this and something will fail an assertion test. */ as Select 1 AS TheKey,'With the data and the dummy routine, you can test to make sure it fails all your automated component tests.' AS TheSentence UNION ALL SELECT 2,'If it passes, you're probably in trouble.' UNION ALL SELECT 3,'Produce a Development harness.' UNION ALL SELECT 4,'In the course of developing T-SQL code, you will occasionally want to know the values in variables, temporary tables and other awkward places.' UNION ALL SELECT 5,'If you have all the time you want, and like developing at about the speed that small mammals evolve, then use an IDE.' UNION ALL SELECT 6,'Otherwise, develop techniques that basically use a temporary log and our own debug code.' UNION ALL SELECT 7,'The simple version of this used to be called 'PrintEffing' (after printf), but here we ''print'' to a simple log that records the time automatically: From then on simple SQL gives you timings for the various components of your routine.' UNION ALL SELECT 8,'You'll also want to know about inefficient code.' UNION ALL SELECT 9,'At this stage, you shouldn't rely on the profiler, Time statistics, the execution plan or extended events to test the performance of code.' UNION ALL SELECT 10,'You need something far more rapid and reliable.' UNION ALL SELECT 11,' I like to use two different types of harnesses, a development harness and a 'verbose' harness to test a stored procedure in actual use.' UNION ALL SELECT 12,'A development-harness is the SQL equivalent of scaffolding, to show how long all the various parts of a long routine are taking. Developers tend not to agree on how to monitor the performance of routines under different data-sizes.' UNION ALL SELECT 13,'I like to know how long a routine took, often every time it is called, and what the parameters were. I also like to be able to pick two points within a routine and know how long it took to run.' UNION ALL SELECT 14,'I like the information immediately, so one can rapidly try out different techniques.' UNION ALL SELECT 15,' I also occasionally like to graph results in Excel.' UNION ALL SELECT 16,' There are subtleties, of course.' UNION ALL SELECT 17,'Do you clear cache before you do a test-run?,Do you force a compilation?' UNION ALL SELECT 18,'It is as well to have the T-SQL to hand to twiddle these knobs, commented out when you don't want them.' UNION ALL SELECT 19,'At this point, I check the database's strategies for audit, error-reporting, and performance monitoring, and comply with them in the harness, as it makes sense to design development and production harnesses together, and an audit obligation could affect performance anyway.' UNION ALL SELECT 20,'So you''ll need TO test, test, test again' UNION ALL SELECT 21,'testing is quite fun anyway' UNION ALL SELECT 21,'to test is good' UNION ALL SELECT 22,'unless something fails a test' |
Now, with a bit of head-scratching, and the use of a simple RegEx in the SSMS ‘find’ dialog-box, we work out that, if we stick rigidly to just displaying fifty characters, the result we need is this, if we search on the word ‘Test’.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ThePrimaryKey StartOfString context ------------- ------------- -------------------------------------------------- 1 46 ...my routine, you can test to make sure it... 1 102 ...ails all your automated component tests. 9 110 ... events to test the performance of code. 11 99 ...o test a stored procedure in actual use. 17 36 ... a test-run?,Do you force a compilation? 20 19 ...So you'll need to test, test, test again 20 25 ...So you'll need to test, test, test again 20 31 ...So you'll need to test, test, test again 21 1 testing is quite fun anyway 21 4 to test is good 22 26 unless something fails a test |
We then construct a view that gives the correct result.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE VIVIEW TestSentenceCorrectResult as SELECT 1 AS PrimaryKey,46 AS startOfString, '...my routine, you can test to make sure it...' AS context UNION ALL SELECT 1,102, '...ails all your automated component tests.' UNION ALL SELECT 9,110, '... events to test the performance of code.' UNION ALL SELECT 11,99, '...o test a stored procedure in actual use.' UNION ALL SELECT 17,36, '... a test-run?,Do you force a compilation?' UNION ALL SELECT 20,19, '...So you''ll need TO test, test, test again' UNION ALL SELECT 20,25, '...So you''ll need TO test, test, test again' UNION ALL SELECT 20,31, '...So you''ll need TO test, test, test again' UNION ALL SELECT 21,1, 'testing is quite fun anyway' UNION ALL SELECT 21,4, 'to test is good' UNION ALL SELECT 22,26, 'unless something fails a test' |
This was an interesting exercise; especially as it fleshed out the underlying rules of where to put the ellipsis, and how to get the context. At this stage I toyed with the idea of always starting and ending the context on a word boundary, but shied away from it for the time being. ‘Let’s do it later if there is time’. I decided. So, component-testing this should be easy by just using our test data and comparing the result with what one would expect. We can do a simple ‘assertion test’ using the same method too. We’ll demonstrate how to make a simple test harness in a moment.
The next thing we need to think about is performance and scalability testing. Here we can get acres of text complete with nasty surprises from any book. Generally, I prefer a million or so rows to test scalability with. It used to be a lot less before SQL Server 2000, but both hardware and software have improved so much that generating test runs has been more tricky. SQL Data Generator can cope well, but the text is just a bit too uniform, so a book it must be.
We can read in a whole book. Here is a routine that will take in a text-based book and read it into a global temporary table, a sentence on each line.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
Create PROCEDURE LoadBook @NameAndPathOnServer VARCHAR(255) /** summary: > This Procedure loads a file into a variable, chops it up into its constituent words and loads it into a global temporary table for subsequent analysis. This is based on code I published in 'The Parodist' Author: Phil Factor Revision: 1.0 date: 19 Jul 2011 example: - - code: EXECUTE LoadBook 'D:\files\sherlockholmes.txt' returns: > 0 if successful. **/ AS SET NOCOUNT on DECLARE @LotsOfText VARCHAR(MAX), @Command NVARCHAR(MAX), @SentenceStart INT, @SentenceLength int, @LotsOfTextLength int; /* We want to read the text file in. Microsoft makes it very hard to use the OpenRowset Bulk with a supplied parameter as a local variable but are we at all discouraged? No Sir, we do a bit of sp_execute.*/ SELECT @Command = 'SELECT @Filecontents = BulkColumn FROM OPENROWSET(BULK ''' + @NameAndPathOnServer + ''', SINGLE_BLOB) AS x' EXECUTE master..sp_executeSQL @Statment = @Command, @params = N'@FileContents VARCHAR(MAX) OUTPUT', @Filecontents = @LotsOfText OUTPUT; /* Read each sentence into a table (we make it a global temporary table as we don't want to keep it for ever!*/ IF EXISTS ( SELECT * FROM tempDB.sys.tables WHERE name LIKE N'##sentence' ) DROP TABLE ##Sentence; /* This gives each sentence in order */ CREATE TABLE ##Sentence (SequenceNumber INT IDENTITY(1,1) PRIMARY KEY, Sentence Varchar(max) NOT NULL); /* now we put all the sentences from the file, in order, into this table */ SELECT @LotsOfTextlength=LEN(@LotsOfText),@SentenceStart=0 WHILE @SentenceStart<@LotsOfTextLength BEGIN SELECT @SentenceStart=@sentenceStart+patINDEX('%[^'+CHAR(0)+'- ]%', RIGHT(@LotsOfText, @LotsOfTextLength-@SentenceStart+1)+' Y. ')-1; SELECT @SentenceLength=1+patINDEX('%[.?!]['+CHAR(0)+'- ]%', RIGHT(@LotsOfText, @LotsOfTextLength-@SentenceStart+1)); INSERT INTO ##Sentence (sentence) SELECT SUBSTRING(@LotsOfText,@SentenceStart,@SentenceLength); SELECT @SentenceStart=@SentenceStart+@SentenceLength; end |
With this in place, we probably have the necessary tools to create a simple test harness.
We can simply run this batch code just to prove that, unless we write some code to provide the functionality, , then the test will fail. I know this sounds obvious but this sort of system catches some very silly common errors
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
DECLARE @Result TABLE ( ThePrimaryKey INT,StartOfString INT,Context VARCHAR( 50 )) -- do stuff here --or check that if the tables are the same it is all OK, by doing this ---- INSERT INTO @result (ThePrimaryKey, StartOfString, context) -- SELECT PrimaryKey, StartOfString, context -- FROM TestSentenceCorrectResult SELECT * FROM @result t FULL OUTER JOIN TestSentenceCorrectResult r ON t.ThePrimaryKey = r.PrimaryKey AND t.StartOfString = r.StartOfString AND t.Context = r.Context ; IF EXISTS ( SELECT * FROM @result t FULL OUTER JOIN TestSentenceCorrectResult r ON t.ThePrimaryKey = r.PrimaryKey AND t.StartOfString = r.StartOfString AND t.Context = r.Context WHERE t.Context IS NULL OR r.Context IS NULL ) RAISERROR('The routine is giving the wrong result', 16,1) ; |
What we have here is a simple test harness. We just add code into the part that has the comment ‘-do stuff here’ until you stop getting errors. Coding is really that easy!
3/ Produce the development harness.
This is going to be quick. We’ll simply use a minimal harness like this. To test it, we’ll just put in three arbitrary points in order to show that they took immeasurable time to execute.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
DECLARE @log TABLE ( Log_Id INT IDENTITY(1, 1),TheeVent VARCHAR( 2000 ), DateAndTime DATETIME DEFAULT GetDate()) ; INSERT INTO @log (TheEvent) SELECT 'first point'; INSERT INTO @log (TheEvent) SELECT 'second point'; INSERT INTO @log (TheEvent) SELECT 'third point'; INSERT INTO @log (TheEvent) SELECT 'end'; SELECT TheStart.TheeVent + ' took ' + CAST( DatedIff( ms, TheStart.DateAndTime, Theend.DateAndTime ) AS VARCHAR( 10 )) + ' Ms.' FROM @log TheStart INNER JOIN @log Theend ON Theend.Log_Id = TheStart.Log_Id + 1; |
4/ Determine the likely best algorithms, assemble the candidates
So we decide we are going to need to use a wildcard search (LIKE and PATINDEX) to find the strings, otherwise the routine won’t be much use. We won’t do a proximity search (two or more words in proximity within a string) since this requires a CLR RegEx function and we’re trying to keep things simple.
The first problem we hit is that a string can be found several times in a column. You will therefore find it tricky to use a join to get the result. Maybe you could use a number table but you’d then have to iterate through the rows . If we can’t do a simple join then there is going to be iteration there. This is something that must be kept to a minimum.
I’ve now got to decide how generic I’d like this to be. Every programmer’s instinct is to make what they write elegant and generic. Here we have an immediate problem in that our code assumes that the primary key of the table, of which we’re searching the string-based column, is an integer. You’ll never win the battle to store primary keys in a generic way. We’ll just have to restrict ourselves to assuming an integer primary key or unique index. Generally, they seem to be!
What sort of routine are we aiming for? I could go for something that searches all possible rows in a database like this one, but here. we are only wanting to search a few columns from a few tables. I decide that a Stored procedure is fine for doing this.
What sort of output do we want? A result? An output variable? Are we outputting a SQL Server result, XML, an XHXHTML fragment?
5/ Sketch out the candidates
The first principle we need to stick to is to access the table that you’re searching as little as possible, so we’ll try to do it just once; when testing out your ideas, it is worth checking the execution plan to make sure that this is happening. Using the test data view, we probably want to just scoop out the likely candidates. We use PATINDEX to find those rows that contain the word ‘test’ and record its first occurrence.
|
1 2 3 4 5 6 7 8 |
DECLARE @Theyreintheresomewhere TABLE (ThePrimaryKey int, TheSentence VARCHAR(2000), [START] int); INSERT INTO @Theyreintheresomewhere(ThePrimaryKey, TheSentence, [START]) SELECT TheKey, TheSentence, startofhits FROM (SELECT TheKey, TheSentence, PATINDEX('%test%',TheSentence) AS startofhits FROM testsentences)f WHERE Startofhits>0; |
A quick check shows us that ‘so far, so good’. We’ve scooped up the rows we want in one pass and determined the location of the first matches of the wildcard ‘%test%’ at the same time.
I try out a few ideas for listing all the matches from the rows of the table. There seem to be two likely candidates. We’ll test them out
6/ Run preliminary performance and scalability tests
Is this SQL that we’ve written any more efficient than a simpler version such as this?
|
1 2 3 4 5 6 7 8 9 10 11 |
DECLARE @Result TABLE ( ThePrimaryKey INT,StartOfString INT,Context VARCHAR( 50 )); DECLARE @Theyreintheresomewhere TABLE ( ThePrimaryKey INT,TheSentence VARCHAR( 2000 ),[Start] INT); INSERT INTO @Theyreintheresomewhere (ThePrimaryKey,TheSentence,[Start]) SELECT TheKey,TheSentence,PatIndex( '%test%', TheSentence ) FROM TestSentences WHERE TheSentence LIKE '%test%'; |
We pop them both into the development harness to check, using the ‘Canterbury Tales’ to test on.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
--first create the temporary log DECLARE @log TABLE ( Log_Id INT IDENTITY(1, 1),TheeVent VARCHAR( 2000 ), DateAndTime DATETIME DEFAULT GetDate()); -- -- first run the 'simple search' INSERT INTO @log (TheEvent) SELECT 'Simple search'; DECLARE @Result TABLE (ThePrimaryKey int, StartOfString int, context varchar(50)) DECLARE @TheyreInThereSomewhere TABLE (ThePrimaryKey int, TheSentence VARCHAR(max), [START] int) INSERT INTO @TheyreInThereSomewhere(ThePrimaryKey, TheSentence, [START]) SELECT Sequencenumber, Sentence, PATINDEX('%test%', Sentence) FROM ##sentence WHERE Sentence LIKE '%test%'; --and now put in the log entry for the end of the simple search and start of the --derived table search INSERT INTO @log (TheEvent) SELECT 'Derived table search'; DECLARE @StringsAreInThisTable TABLE (ThePrimaryKey int, TheSentence VARCHAR(max), [START] int) INSERT INTO @StringsAreInThisTable(ThePrimaryKey, TheSentence, [START]) SELECT TheKey, TheSentence, startofhits FROM (SELECT SequenceNumber AS TheKey, Sentence AS TheSentence, PATINDEX('%test%',Sentence) AS startofhits FROM ##sentence)f WHERE Startofhits>0; --we need to add this log entry to make the extraction of the timings easier INSERT INTO @log (TheEvent) SELECT 'end' --now we just report the comparative timings SELECT TheStart.TheeVent + ' took ' + CAST( DatedIff( ms, TheStart.DateAndTime, Theend.DateAndTime ) AS VARCHAR( 10 )) + ' Ms.' FROM @log TheStart INNER JOIN @log Theend ON Theend.Log_Id = TheStart.Log_Id + 1; |
It turns out that they have almost identical timings, at 250 Ms, and a quick look at the execution plans shows why: they generate identical plans on our test data. We can safely use the simpler version for the time being.
We then turn our attention to producing the matches.
We can take the procedural approach
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
SET NOCOUNT ON DECLARE @ii INT,--the row we are checking @jj INT,--the position in the string of the match @rowcount INT,--the number of rows to search @sentence VARCHAR(MAX),--the text of the sentence @PrimaryKey INT,--the primary key of the string @MATCH INT-- the index into the substring we are searching. DECLARE @Theyreintheresomewhere TABLE ( TheIdentityColumn INT IDENTITY(1, 1) PRIMARY KEY,ThePrimaryKey INT, TheSentence VARCHAR( 8000 ));--all sentences that had a match DECLARE @Result TABLE (--the result table with the matches ThePrimaryKey INT,StartOfString INT,Context VARCHAR( 50 )); INSERT INTO @TheyreInThereSomewhere (ThePrimaryKey,TheSentence) SELECT SequenceNumber,Sentence FROM ##Sentence WHERE Sentence LIKE '%body%'; --set up the row counter SELECT @ii=1,@jj=1, @RowCount=COUNT(*) FROM @TheyreInThereSomewhere; --hidden cursor! WHILE (@ii<=@RowCount) BEGIN WHILE @jj>0 BEGIN SELECT @match = PATINDEX('%body%',RIGHT(TheSentence,LEN(TheSentence+'!')-@jj)), @PrimaryKey=ThePrimaryKey, @Sentence=TheSentence FROM @TheyreInThereSomewhere WHERE TheIdentityColumn=@ii; IF @Match=0 BREAK; SELECT @jj=@jj+@Match-1; INSERT INTO @Result(ThePrimaryKey, StartOfString, context) SELECT @PrimaryKey, @jj, CASE WHEN LEN(@Sentence)<40 THEN @Sentence WHEN LEN(@sentence)-@jj< 40 THEN '...'+ RIGHT(@Sentence,40) WHEN @jj<30 THEN LEFT(@jj,40)+'...' ELSE '...'+SUBSTRING(@Sentence,@jj-20,40)+'...' END; SELECT @jj=@jj+1; END SELECT @jj=1, @ii=@ii+1; END |
(I developed this with the small result set, checking with the test result, and then searched for the substring ‘body’ in the Canterbury Tales. Hmm, quick. Even the iteration part only takes 70Ms with a reasonably small result.
We can do better. If we use this algorithm, we get the second part to 6 Ms, measured with the test harness. The scan of the entire Canterbury Tales took only 240 Ms.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
DECLARE @Result TABLE ( ThePrimaryKey INT,StartOfString INT,Context VARCHAR( 50 )); DECLARE @StringsAreInThisTable TABLE ( ThePrimaryKey INT,TheSentence VARCHAR( MAX ),[Start] INT); DECLARE @Start INT ; SET NoCount ON INSERT INTO @StringsAreInThisTable (ThePrimaryKey,TheSentence,[Start]) SELECT SequenceNumber,Sentence,PatIndex( '%body%', Sentence ) FROM ##Sentence WHERE Sentence LIKE '%body%' ; WHILE (1=1) BEGIN INSERT INTO @Result(ThePrimaryKey, StartOfString, context) SELECT ThePrimaryKey, START, CASE WHEN LEN(<(TheSentence)<40 THEN TheSentence WHEN LEN(TheSentence)-Start< 40 THEN '...'+ RIGHT(TheSentence,40) WHEN Start<30 THEN LEFT(Start,40)+'...' ELSE '...'+SUBSTRING(TheSentence,Start-20,40)+'...' end FROM @StringsAreInThisTable WHERE start >0; IF @@Rowcount=0 BREAK UPDATE @StringsAreInThisTable SET @start=PATINDEX('%body%',RIGHT(TheSentence,LEN(TheSentence+'!')-start-1)), START=CASE WHEN @Start=0 THEN 0 ELSE @Start+start end WHERE start >0; END |
In doing this exercise, I’ve noticed how bad the context search strings look with returns and linefeeds in them, and how silly the margin looks in the text file. I also wonder whether they’d be improved by showing exactly where in the displayed string the match took place. If I get time, I’ll go back and improve that, but for the time being I’ll press on and get something running, since with the test and dev harness worked out, this can be done quickly.
7/ Build
We are now at the point where we can be reasonably confident that the routine is working right, but we can save the test scripts we’ve done in case we find a bug and have to revert, or if we have time for improvements.
I like to delay creating a procedure or function as long as I can just because it is so much easier to do component testing on the various component blocks of logic (e.g. WHILE loops) and expressions, and it is good to be able to look at intermediate results.
AtAt this stage, I felt confident enough that things were working well enough to encapsulate the logic in the stored procedure.
I’d soon popped in comments, a header, improved the variable names here and there and generally tidied it up. I parameterized all the obvious things that would benefit from being parameterized. I turned it into a generic routine that would work for any table. A glance at the clock showed me I was well ahead of the allotted time. I I was still niggled by the fact that the context of the match was wrong. I’d decided that it would be OK to break the context anywhere rather than at a word boundary, and the job that required the code could be done with what I’d delivered, but it looked tatty so I redid the code so that, instead of …
|
1 2 3 4 5 6 7 |
ThePrimaryKey StartOfString context ------------- ------------- -------------------------------------------------- 1 46 ...my routine, you can test to make sure it... 1 102 ...ails all your automated component tests. 9 110 ... events to test the performance of code. 11 99 ...o test a stored procedure in actual use. ... etc ... |
It looked like…
|
1 2 3 4 5 6 7 |
ThePrimaryKey StartOfString Context ------------- ------------- ------------------------------------------------ 1 46 ... dummy routine, you can test to make sure it... 1 102 ...fails all your automated component tests. 9 110 ...events to test the performance of code. 11 99 ...to test a stored procedure in actual use. ... etc ... |
The next part of the build process was to test it out on a number of databases and tables. As is often the case, each new table I tried it on threw up a new difficulty. Although I’d put in a few diagnostics, I wished at this stage I’d done a few more as it would have speeded this process. I had a lot of fun with Chaucer’s ‘the Canterbury Tales.’ It is always a surprise to find such words were in the classics.
8/ Unit Test
Whilst doing bug-fixes in the light of testing, on various sizes and types of text-based columns, I did a simple unit test to make sure I’d not broken anything. This is so unobtrusive that it can be added to the build script, or used for regular checks. Although I’ve tried to pretend that these phases of developing a procedure are distinct, there is actually quite a bit of leaping back and forth between phases in response to finding a bug, or improving the result. However, in the Unit Test phase, it is now time to set up at least one simple automated test to run whenever you make a change. Here is the one I used, based on the test harness I showed you earlier.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DECLARE @Result TABLE ( ThePrimaryKey INT,StartOfString INT,Context VARCHAR( 2000 )) ; -- do stuff here INSERT INTO @result (ThePrimaryKey,StartOfString,Context) EXECUTE SearchTableColumn 'TestSentences','TheSentence','TheKey', 'test', 50; SELECT * FROM @result t FULL OUTER JOIN TestSentenceCorrectResult r ON t.ThePrimaryKey = r.PrimaryKey AND t.StartOfString = r.StartOfString AND t.Context = r.Context ; IF EXISTS ( SELECT * FROM @result t FULL OUTER JOIN TestSentenceCorrectResult r ON t.ThePrimaryKey = r.PrimaryKey AND t.StartOfString = r.StartOfString AND t.Context = r.Context WHERE t.Context IS NULL; OR r.Context IS NULL ) RAISERROR('The routine is giving the wrong result', 16,1); |
I also ran a number of checks on a number of databases I have lying around to make sure that nothing else is obviously broken.
9/ Check-in
I I like the finality of the check-in. Time’s up, and I’m running a time-box on this routine. The paint is still a little bit wet, but it is time to nip out to the pub. It is pointless to describe the nuts and bolts of Check-in: it is just a handy way to end an article. You’ll probably be using SQL Source Control, a piece of software that is close to my heart. As a punishment, I’m forcing myself to use GIT raw so I can encourage others to improve some of my work, and start to do some collaborative work! The current version of the stored procedure can be downloaded at the bottom of the article.
Here is the state of play with the routine
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
CREATE PROCEDURE SearchTableColumn /** summary: > This Procedure searches through whatever strings are loaded into a the table called @TableName, and produces a result of all the matches in a column called @StringColumnName, in context' Author: Phil Factor Revision: 1.0 date: 21 Jul 2011 example: - - code: EXECUTE SearchTableColumn 'testSentences','TheSentence','TheKey', 'test', 40 - code: EXECUTE SearchTableColumn 'production.document','DocumentSummary','Documentid', 'cycle', 40 - code: EXECUTE SearchTableColumn '##sentence','sentence','SequenceNumber', 'pain', 20 returns: > result ThePrimaryKey INT,StartOfString INT,Context VARCHAR( 8000 )) **/ @TableName SysName,--the name of the table. e.g. production.document, databaseLog @StringColumnName Sysname,--the name of the column to search. e.g. Documentsummary, T-SQL @KeyColumnName Sysname,--the name of the integer column that distinguishes the matched row @StringTosearch VARCHAR(100),--the string to search for. @ContextWidth INT = 40 AS -- DECLARE @Result TABLE ( ThePrimaryKey INT,StartOfString INT,Context VARCHAR( 8000 ));--the generic result table create table #StringsAreInThisTable ( ThePrimaryKey INT,TheSentence VARCHAR( MAX ),[Start] INT); DECLARE @Start INT, @Command NVARCHAR(MAX); SET NoCount ON --check that the table exists IF NOT EXISTS ( SELECT * FROM sys.objects WHERE Name LIKE PARSENAME(@TableName,1) AND type IN ('v','u' )) BEGIN RAISERROR('The TABLE or VIEW ''%s'' does not exist in this database', 16, 1, @TableName); RETURN 0 END -- and that the column to search exists IF NOT EXISTS ( SELECT * FROM sys.columns WHERE Name LIKE @StringColumnName AND [object_id]=object_ID(@TableName)) BEGIN RAISERROR('The TABLE or VIEW ''%s'' does not have a column to search called ''%s''', 16, 1, @TableName,@StringColumnName); RETURN 0 END --can this column contain a string? IF NOT EXISTS ( SELECT * FROM sys.columns AS c INNER JOIN sys.types AS ty ON c.user_type_id = ty.user_type_id WHERE ty.name IN ('char','nchar','nvarchar','varchar','text', 'ntext', 'xml', 'sql_variant') AND c.Name LIKE @StringColumnName AND c.[object_id]=object_ID(@TableName)) BEGIN RAISERROR('The column %s in TABLE or VIEW ''%s'' can not be converted to a string', 16, 1, @StringColumnName, @TableName); RETURN 0; END --is the supplied key column an integer, at least IF NOT EXISTS ( SELECT * FROM sys.columns AS c INNER JOIN sys.types AS ty ON c.user_type_id = ty.user_type_id WHERE ty.name IN ('int', 'bigint') AND c.Name LIKE @KeyColumnName AND c.[object_id]=object_ID(@TableName)) BEGIN RAISERROR('The column %s in TABLE or VIEW ''%s'' is not an integer so can not be used to distinguish a matched row', 16, 1, @KeyColumnName, @TableName); RETURN 0; END --create the command to fill our table with data. SELECT @command='INSERT INTO #StringsAreInThisTable (ThePrimaryKey, TheSentence, [START]) SELECT TheKey, TheSentence, PATINDEX(''%'+@StringToSearch+'%'',TheSentence) AS startofhits FROM (SELECT '+@KeyColumnName+' AS TheKey, REPLACE( REPLACE( REPLACE( Replace( Replace( Replace(Cast ('+@StringColumnName+' as varchar(max)),CHAR(32),CHAR(32)+CHAR(160)), CHAR(160)+CHAR(32),''''), CHAR(160),'''' ), CHAR(10),'' ''), CHAR(13),'' ''), '' '', '' '') AS TheSentence FROM '+@Tablename+' WHERE Cast ('+@StringColumnName+' as VARCHAR(MAX)) LIKE ''%'+@StringToSearch+'%'')f'; Exec sp_ExecuteSQL @Command; WHILE (1=1)--for ever until we hit a BREAK (see below) BEGIN INSERT INTO @Result(ThePrimaryKey, StartOfString, context) SELECT ThePrimaryKey, START, --we extract the context CASE WHEN LEN(TheSentence)<@contextWidth THEN TheSentence--since there is no need to truncate the line WHEN LEN(TheSentence)-Start< @contextWidth THEN '...'+ RIGHT(TheSentence, CHARINDEX(' ',REVERSE(TheSentence)+' ',@contextWidth)-1 )--just take off all but the end -- we can just show the end as there is space WHEN Start<(@contextWidth-10) THEN RTRIM(LEFT(TheSentence,CHARINDEX(' ',TheSentence+ ' ',@contextWidth)-1)) +'...' --we truncate the end and just show the start ELSE '...' --in this case, we take a deep breath and do it properly. +RIGHT( left(TheSentence,Start-(@contextWidth/2)-1), CHARINDEX(' ',REVERSE(left(TheSentence,Start-(@contextWidth/2)-1))) )--the remains of the severed word at the beginning +SUBSTRING(TheSentence,Start-(@contextWidth/2),@contextWidth)--the slice of text +SUBSTRING(TheSentence, --the remains of the severed word at the end Start+(@contextWidth/2), CHARINDEX(' ',TheSentence+ ' ',Start+(@contextWidth/2))-(start+(@contextWidth/2))) +'...' end FROM #StringsAreInThisTable WHERE start >0 IF @@Rowcount=0 BREAK --nothing more to do UPDATE #StringsAreInThisTable --set the location of the next match SET @start=PATINDEX('%'+@StringToSearch+'%',RIGHT(TheSentence,LEN(TheSentence+'!')-start-1)), START=CASE WHEN @Start=0 THEN 0 ELSE @Start + start end WHERE start >0 --don't bother with the ones that have no more hits in the string END SELECT ThePrimaryKey, StartOfString, Context FROM @result ORDER BY ThePrimaryKey, StartOfString; |
Conclusions
There is a certain terror in disclosing the processes behind coming up with a T-SQL routine. It is much cosier to pop up with the finished T-SQL as if one wrote it like a Shakespearian sonnet. It belies the actual errors, dead ends, and frustrations that are part of the process. This is probably why it is rare to see the actual process explained in detail. This article will be pretty meaningless unless you have read the first article in this series, How to develop T-SQL Code. Once again, I’d caution you that this method works for me but you’ll probably find that every SQL developer has a different way. Hopefully, this article will encourage some other accounts of how to be a productive SQL programmer.
This document contains proprietary information and is protected by copyright law.
Copyright © 2026 Red Gate Software Limited. All rights reserved






Load comments